Identity Resolution vs Identity Graph: Why It Matters for Ecommerce Growth

When trying to identify visitors, many ecommerce brands mistakenly use identity resolution and identity graph interchangeably. They sound similar, but they solve different problems.
Identity resolution is the process of connecting identifiers like email addresses, phone numbers, device IDs, and IPs into a single, unified customer profile. Without it, you end up with duplicates, half-complete records, and wasted ad spend.
An identity graph is the system that makes resolution possible. It stores identifiers, maps their relationships across channels, and enforces consent rules like GDPR and CCPA.
Understanding the distinction matters. Without a clear strategy for both, customer data fragments across CRMs, apps, ad platforms, and in-store systems. This results in duplicates, incomplete records, and missed revenue opportunities from anonymous visitors who never make it into your CRM.
When you get them working together, you build accurate profiles at scale, translating into higher conversion rates, stronger customer retention, and lower acquisition costs.
Background reading: key definitions you need to know
Before comparing identity resolution and identity graphs, it’s important to get clear on the basics. These terms often get used interchangeably, but they play different roles in customer data management.
Identity resolution
Identity resolution is the process of stitching together identifiers across mobile devices, channels, and sessions.
Think of an email address captured from a checkout form, a phone number entered into a loyalty program, and a device ID recorded from a mobile app. Resolution algorithms connect these identifiers into a single profile so you can recognize the same customer wherever they interact with your brand.
Done poorly, it leads to wasted ad spend, flawed personalization, and broken deliverability because your CRM is cluttered with low-quality or duplicate entries. Done correctly, identity resolution eliminates duplicates, prevents fragmented records, and gives you a clean and comprehensive view of the individual customer journey.
Tools like Tie can identify and enrich up to 90% of anonymous visitors, giving you a high-quality identity graph that powers every downstream campaign, from Klaviyo flows to Meta retargeting.
Book a demo to see how it works in action.
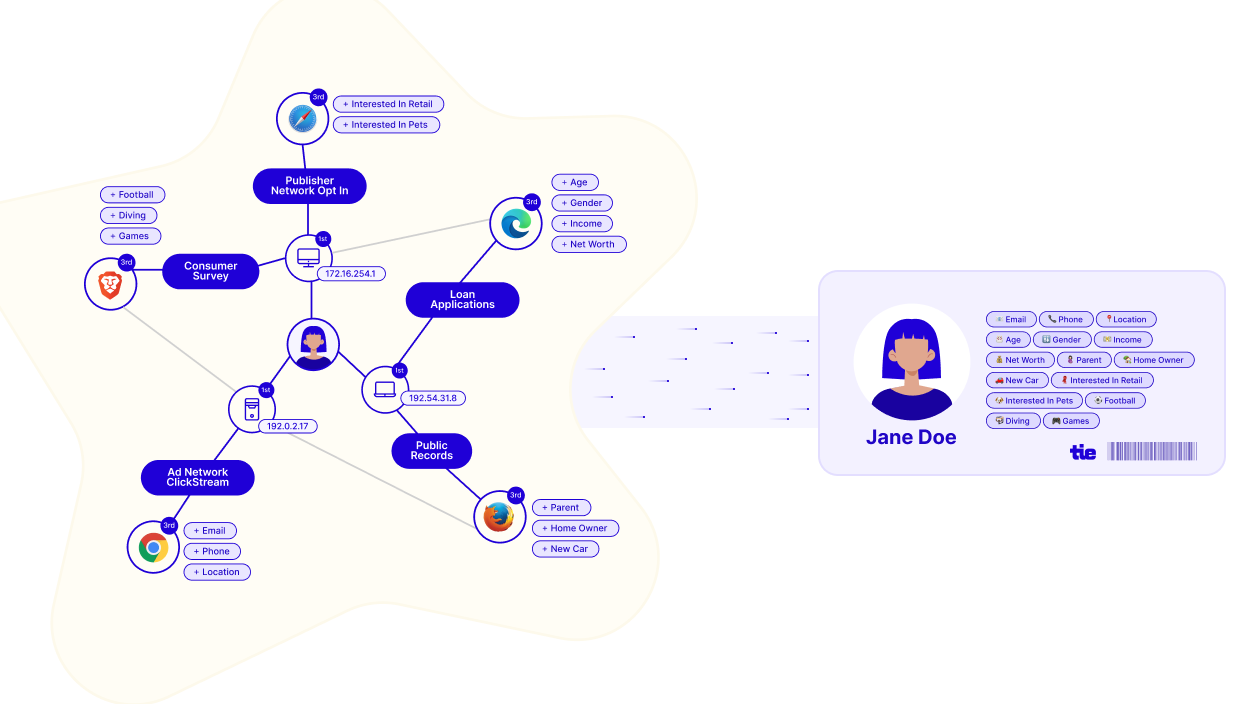
Deterministic vs probabilistic
Every identity resolution solution relies on two approaches:
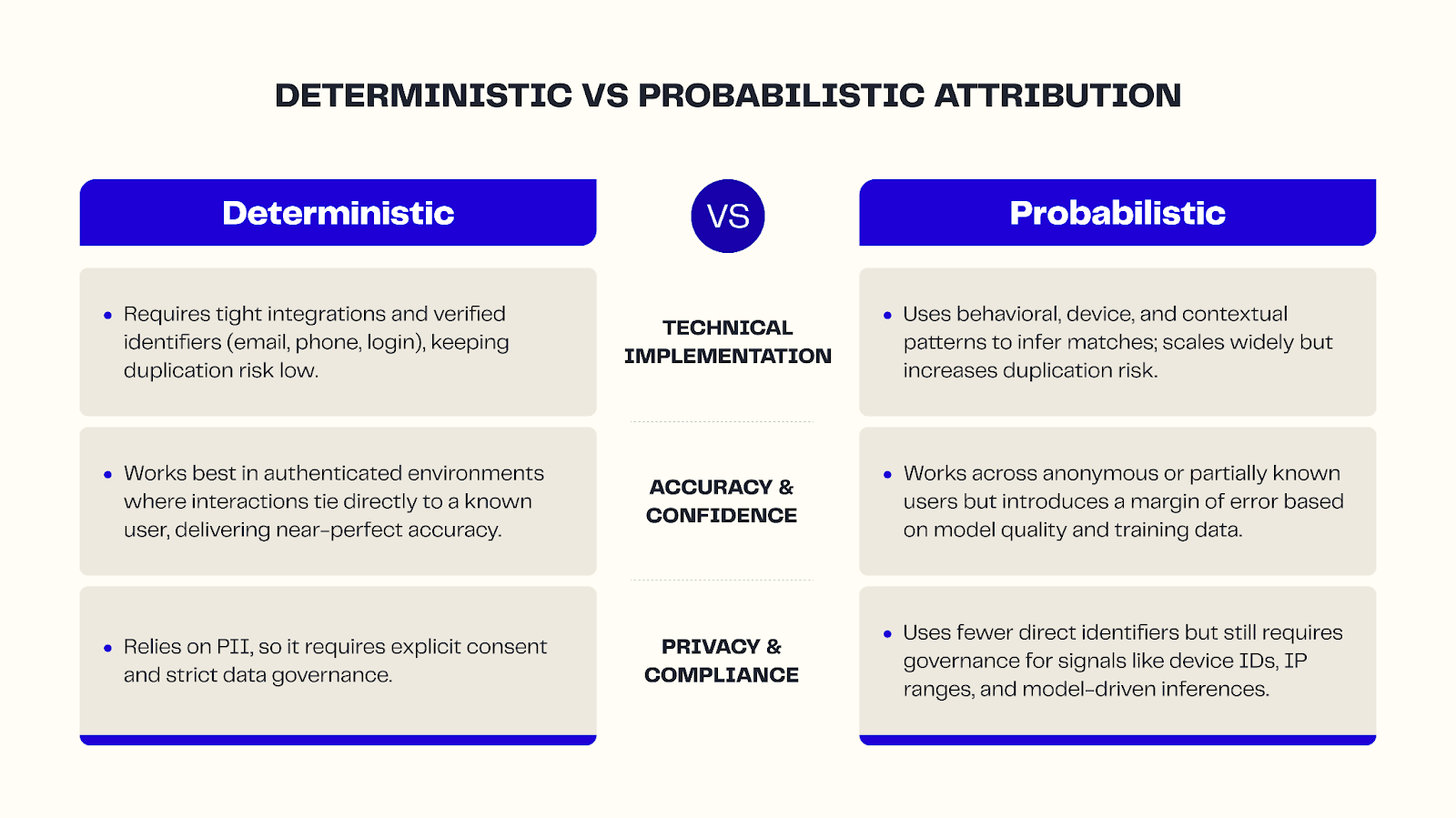
- Deterministic matching: Exact matches between identifiers, such as the same phone number appearing in two different systems. It’s highly accurate but limited to the identifiers you collect.
- Probabilistic matching: Algorithms and statistical models infer connections based on behavior and technical signals (IP addresses, device fingerprints, browsing patterns). This extends your reach but requires careful data governance to maintain accuracy.
The strongest solutions combine both. First-party data (emails, logins, loyalty IDs, and verified consented records) form the foundation, while probabilistic methods then enrich these user profiles, filling gaps when deterministic matches aren’t available.
Identity graph
An identity graph (sometimes called a customer identity graph or first-party identity graph) is the underlying data structure that stores and manages these connections.
It links identifiers into a persistent network, maps relationships across channels and devices, and enforces governance rules like General Data Protection Regulation (GDPR), California Privacy Right Act (CPRA), or California Consumer Privacy Act (CCPA) compliance.
For example, when a shopper logs in with social credentials or makes an in-store purchase tied to their phone number, the identity graph connects that new data to the existing profile in real time. Without this infrastructure, even strong resolution work remains stuck in silos.
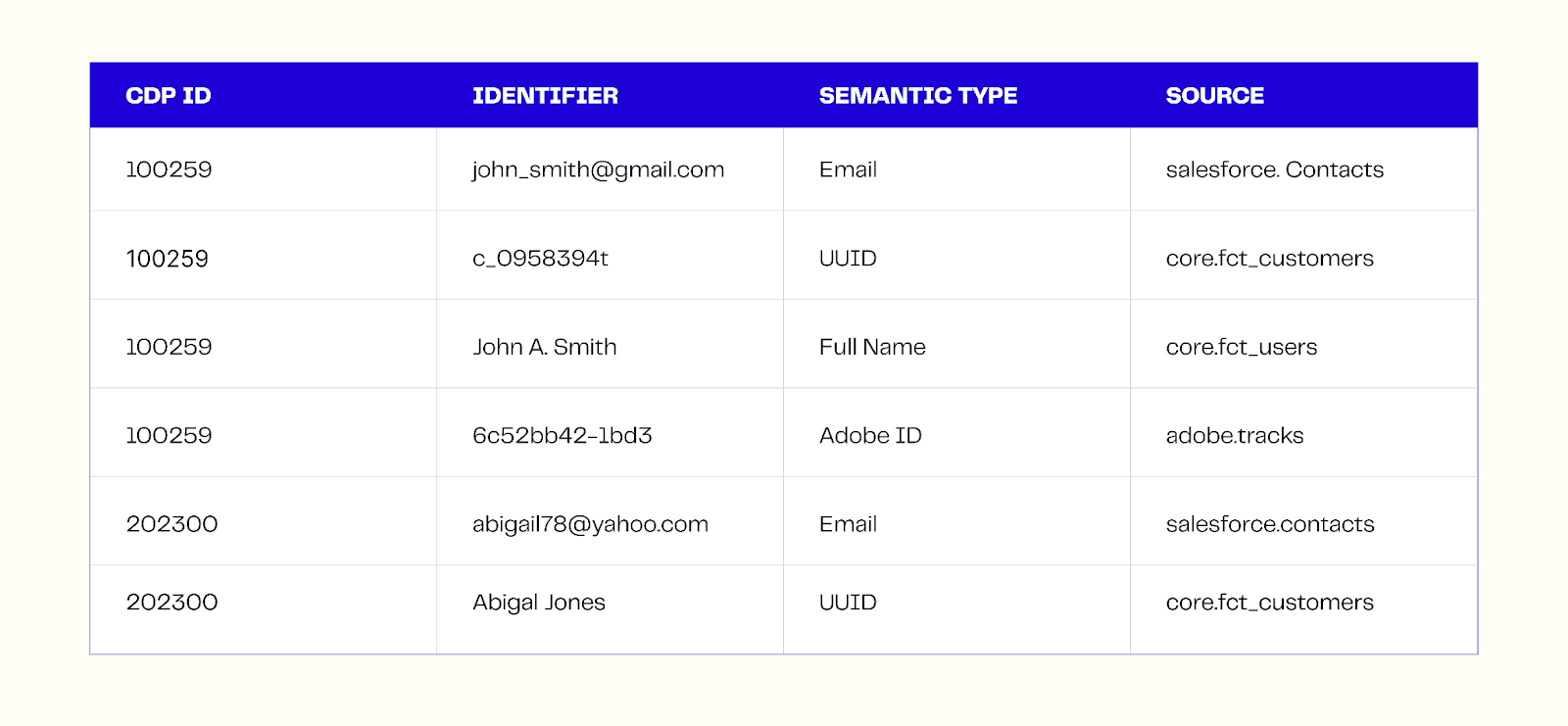
Difference between identity graph and identity database
A lot of platforms say they have an “identity graph,” but what they actually have is an identity database. The difference is crucial because a database stores identities, while a graph understands relationships between them.
An identity database keeps rows of profiles, but relationships must be calculated each time through queries. This means that cross-device, cross-session, or cross-household connections decay or break unless manually refreshed.
An identity graph, by contrast, is built on a graph or vector structure designed for real-time linking.
Every session, device ID, email, and household signal becomes a node in a graph that can connect non-linearly to many others without reprocessing the entire dataset.
So, when a new session surfaces from the same household, the graph updates the relationship instantly. When one user switches devices, the graph maintains continuity. When a profile evolves, the stitched identity evolves without waiting on batch jobs or re-queries.
This is the layer that lets Tie reconcile anonymous visits, cross-browser journeys, and multi-household interactions automatically— something traditional relational databases simply weren’t built to do.
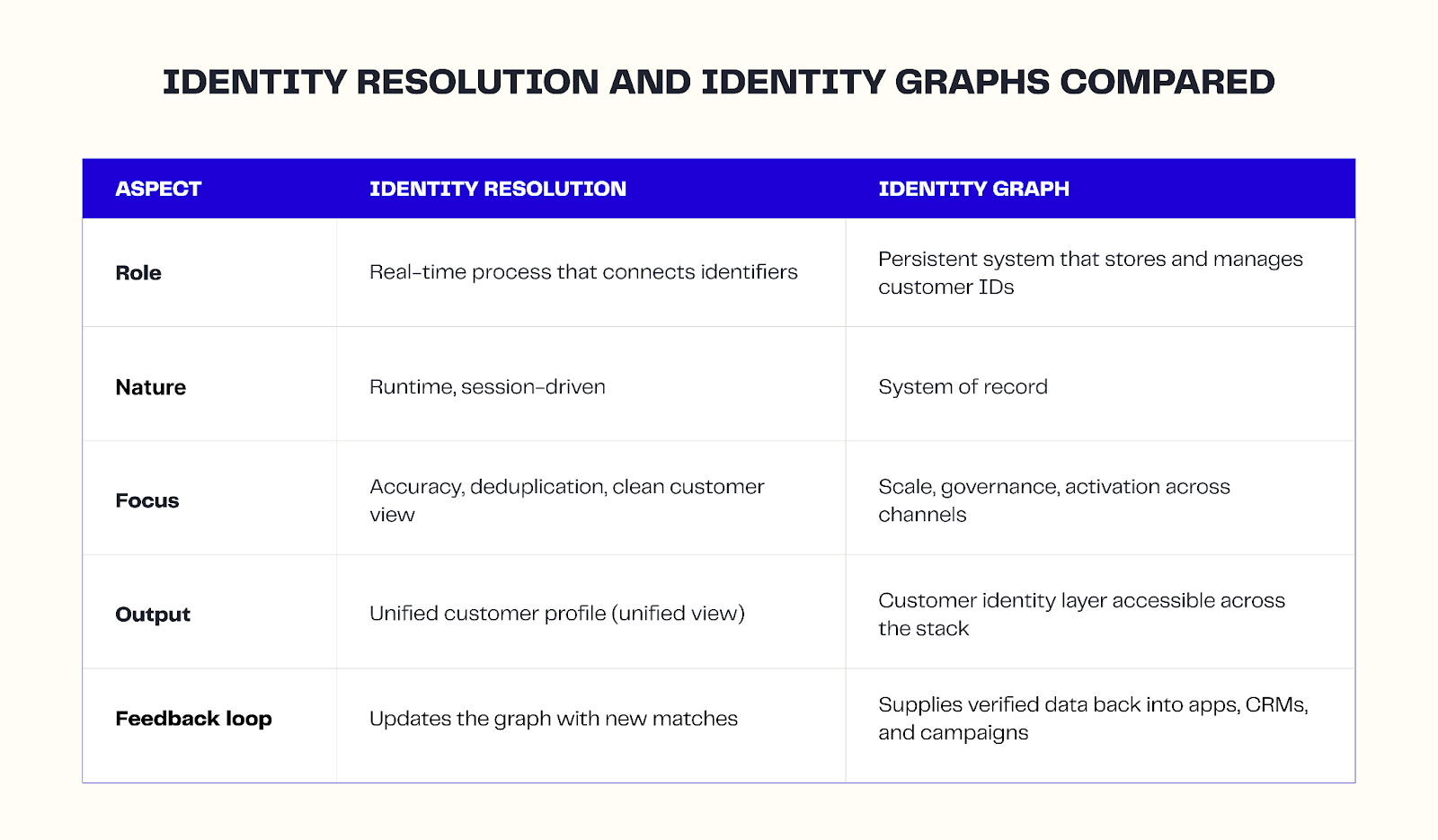
Similarities and differences between identity resolution and graphs
You need both identity resolution and an identity graph to build a reliable customer identity layer. They complement each other, but they serve different roles. Resolution is the process that runs in real time, whereas the graph is the system of record that makes those results usable across your entire stack.
Together, they form a feedback loop: resolution feeds fresh identifiers into the graph, and the graph distributes accurate, governed data downstream to every activation layer: email flows, retargeting campaigns, loyalty programs, and more.
Where the identity graph lives
Your identity graph can sit inside a customer data platform (CDP) or a data warehouse, but each comes with trade-offs:
- A CDP surfaces the graph for direct activation. It lets you sync enriched customer profiles straight into Klaviyo, Meta, or SMS platforms, making it ideal for retention and personalized email flows.
- A data warehouse prioritizes scale and advanced analytics. It stores and analyzes identity data alongside other large datasets. Activation usually requires engineering resources and custom pipelines.
Most ecommerce brands choose a hybrid setup. The graph lives in the warehouse for scale, while a CDP pipes it into marketing tools for speed of execution.
For a deeper breakdown, explore our guide on B2C contact databases, where customer data is stored, and how it gets activated.
Where revenue shows up
The impact of identity resolution and an identity graph shows up directly in your revenue metrics. When you resolve more identifiers and maintain them inside a clean, governed graph, three levers drive measurable lift:
- Reach: You identify more visitors and add them to your CRM. Instead of losing 40–50% of site traffic to anonymity, you build larger, verified audiences for email, SMS, and paid retargeting.
- Relevance: You segment more accurately. Unified customer profiles combine browsing data, purchase history, and channel engagement, so you can personalize offers instead of relying on generic flows.
- Frequency control: You prevent over-messaging by tracking the same customer across channels. This avoids duplication and improves email deliverability, keeping customer engagement high.
Revenue plays tied to KPIs
Here’s how resolution and graphs power tactical plays that you can run instantly:
- Abandoned cart flows: When anonymous visitors are identified, including verified emails or phone numbers, they can re-enter your email flows. Recovery rates increase, especially when paired with identity graph enrichment like purchase intent or device type.
- Win-back campaigns: Deduplicating and refreshing old records reconnects you with churned buyers, lifting repeat purchase rates and LTV.
- Cross-sells and upsells: Graph enrichment surfaces product affinities (e.g., buyers of denim often buy accessories), letting you send targeted offers that increase order value.
These have a positive impact on the KPIs that matter most:
- Deliverability improves since low-quality or duplicate identifiers never enter your sends.
- LTV/CAC rises as you capture more revenue from existing customers without raising customer acquisition costs.
- Paid ROAS lifts since you now retarget real, high-intent shoppers instead of wasting impressions on anonymous clicks.
When you combine these levers, customer identity resolution stops being just a technical process. It becomes a revenue channel, turning anonymous traffic into activated customers and improving retention with every campaign.
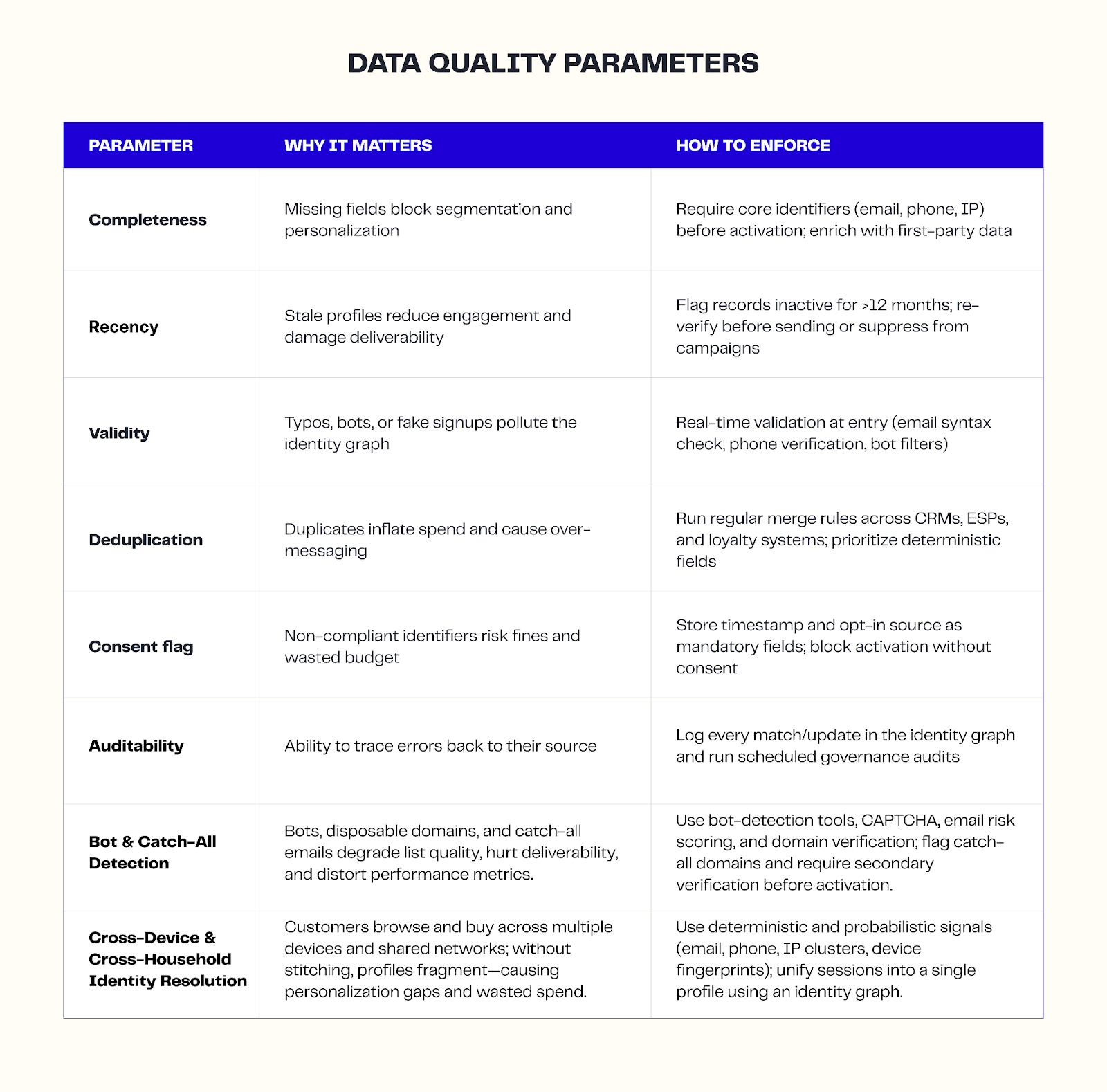
Data quality requirements for identity resolution and graphs
The accuracy of your identity resolution and the reliability of your identity graph depend on the quality of the data you feed them. If identifiers are incomplete, outdated, or unverified, you’ll end up with broken customer profiles, poor deliverability, and wasted ad spend.
To maintain data quality, high-performing ecommerce teams focus on four principles:
1. Validate and standardize before matching
Identifiers need to be clean and consistent: emails without typos, phone numbers with proper country codes, and addresses standardized for postal rules.
When you normalize data upfront, identity resolution algorithms make accurate deterministic matches instead of failing silently or generating duplicates.
2. Track quality parameters at the profile level
Don’t just store identifiers. Measure them. Every profile in your customer identity graph should be validated for:
- Completeness: Are the core fields (email, phone, consent) present?
- Recency: When was the last verified customer interaction?
- Validity: Was consent captured?
If a profile falls below the threshold (for example, the email hasn’t been active for a year), it should be gated from activation until refreshed. This prevents bad data from dragging down deliverability or skewing segments.
3. Make consent a first-class field
Every identifier in the graph should include a timestamped consent flag. This guarantees that personally identifiable information (PII) is always processed in line with GDPR, CCPA, and other regional laws.
Without it, you risk both compliance penalties and wasted spend on audiences who should never be targeted.
4. Governance checkpoints keep the graph reliable
Set up processes that audit how identifiers are stitched together. If you lean too heavily on probabilistic matching, you risk inflating audience size with false positives. If you never log changes, you can’t trace bad data back to its source.
Strong governance means visible match rules, version histories, and automated checks before any new profile is activated downstream.
The challenge most brands miss
The biggest challenge with maintaining data quality is keeping identifiers reliable as they evolve. Customers switch devices, change email addresses, and update phone numbers constantly.
Without recency checks and deduplication logic, your identity graph bloats with outdated records. That leads to over-messaging, wasted budget, and declining ROAS.
That’s why you shouldn’t measure success by how much data your identity stack holds. Measure it by how clean, current, and compliant the data is. A smaller, higher-quality graph will always outperform a bloated one.
Build vs. buy decision
Deciding whether to build your own identity resolution system and identity graph or buy a proven solution is one of the highest-leverage calls you’ll make. It impacts how quickly you can act on customer insights, how accurate your profiles remain, and how much engineering overhead your team carries.
Coverage and match accuracy
If you build in-house, you’re limited to the identifiers you can collect directly (checkout emails, loyalty IDs, or app logins). These coverage gaps leave many visitors anonymous.
Buying a commercial identity graph gives you access to billions of verified identifiers and optimized matching algorithms, delivering higher match rates and cleaner customer profiles from day one.
Latency and activation
Identity resolution works only if it happens instantly. Self-built systems often lag since they connect data across multiple tools without real-time pipelines. That delay means abandoned carts go cold before you can trigger automated recovery flows.
Buying avoids this bottleneck. Purpose-built graphs resolve and sync profiles into Klaviyo, Meta, and your CRM within seconds, letting you act while shopper intent is still fresh.
Privacy posture and governance
When you build, you own the burden of privacy regulations. You need engineers and legal teams to manage GDPR or CCPA consent flags, run audits, and maintain logs. Missing one checkpoint can risk fines or block your campaigns.
Buying shifts that load to a vendor that treats consent as a first-class field, with governance and auditability built into the identity graph. Even mid-market ecommerce brands benefit from these enterprise-grade controls.
Cost and speed-to-value
Building looks cheaper until you factor in the hidden costs: engineering headcount, integrations, data vendor contracts, and constant maintenance. A typical internal identity stack costs $300K–$600K per year and takes 6–12 months before it meaningfully impacts ROI. Buying shortens that timeline.
A purpose-built platform like Tie starts at $499/month (300K credits/year), and activates in days or weeks, not quarters.
That means you can begin resolving anonymous visitors immediately, push them into your existing channels, and see revenue lift within weeks instead of waiting for a long build cycle.

Implementation blueprint
Implementing identity resolution with an identity graph isn’t just about connecting systems. You need a framework that captures identifiers from every touchpoint, applies clear merge and suppression rules, and pushes updates quickly enough to power revenue-driving flows.
You can break this process down into three steps:
1. Ingest identifiers from all critical data sources
Instead of letting browsers collect fragmented signals, Tie captures identifiers server-side — where data is stable, durable, and not dependent on cookies.
This includes:
- Web and app events streamed from servers (session IDs, device signatures, behavioral signals)
- CRM and ESP data, like emails, purchase history, and engagement activity.
Each server-side signal fills gaps and steadily shrinks the share of anonymous visitors that slip through your ecosystem.
2. Define a Golden ID policy and merge logic
Instead of forcing every profile to anchor to a single email or phone number, Tie creates an RRID— a resilient, AI-generated identifier that approximates a household or identity cluster. This lets you:
- Stitch cross-device and cross-session behavior (even when emails don’t match).
- Resolve anonymous and partial identities into a unified customer graph.
- Avoid brittle merge rules that depend on a single identifier.
With RRID, identity resolution isn’t constrained by missing emails or mismatched logins. The system infers continuity, so more visits, carts, and purchases attach to a living profile rather than fragmenting into dead records.
3. Keep profiles fresh with near real-time updates
Identity resolution is only valuable if it happens fast. A cart recovery email that lands tomorrow is a missed opportunity. Configure your graph to:
- Update profiles instantly when new identifiers are captured.
- Sync refreshed data into Klaviyo, Meta, and SMS tools within seconds.
- Block activation for profiles that don’t meet quality thresholds (recency, consent, completeness).
Ready to identify more of your traffic with identity resolution?
Effective identity resolution gives you the process to unify identifiers. An identity graph gives you the system to store and activate them. Together, they form the customer identity layer that powers every revenue play: cart recovery, win-back, cross-sell, retention, and paid efficiency.
With Tie, you can:
- Resolve anonymous visitors into verified profiles and add them directly into Klaviyo or your CRM.
- Recover high-intent sessions with real-time cart abandonment flows.
- Improve deliverability by filtering out duplicates and invalid records before they hit your ESP.
- Lift retention by running win-back and cross-sell campaigns on a clean, unified customer profile base.
Brands like Hollow used Tie to identify anonymous visitors and grew their list by 50% in just two months, turning missed traffic into net-new revenue.
Ready to see how much traffic you’re missing? Book a demo!
Identity resolution vs identity graph FAQs
Do I need a first-party identity graph if I already have analytics?
Yes, you need a first-party identity graph if I already have analytics.
Analytics tells you what happened (page views, bounce rate, conversions), but it doesn’t unify identifiers across channels. A first-party identity graph creates persistent single customer profiles that your campaigns can actually act on.
Will identity resolution systems replace analytics?
No. Identity resolution software like Tie complements analytics. Analytics explains performance while the identity graph makes sure that you’re tracking and targeting the right people in the first place.
What if consent is low?
Identity resolution only works if customers opt in. You can improve consent rates with on-site value exchange tactics like loyalty rewards, early access, or personalized recommendations. This grows your identity graph with verified, first-party data.
Do I need both identity resolution and an identity graph?
Yes. Identity resolution is the process of stitching identifiers, while the graph is the system that stores and governs them.
Without both, you either stay stuck with fragmented data or you can’t scale your resolution across channels.
How do identity tools recover carts and increase lifecycle revenue?
By resolving anonymous visitors into known profiles, you can trigger abandoned cart flows, win-back journeys, and personalized cross-sells that wouldn’t be possible otherwise.
Every resolved identifier makes your lifecycle campaigns more complete and more profitable.
Which data quality checkpoints matter for identity stitching?
The key data quality checkpoints are:
- Completeness: Every profile needs core identifiers (email, phone, device ID).
- Recency: Stale records drag down deliverability.
- Validity and consent: Every identifier must be verified and opted in.
- Deduplication: Merge rules stop duplicate profiles from inflating lists or causing over-messaging.
How do I measure ROI from identity-driven programs?
To measure ROI from identity-driven programs, track incremental revenue from audiences you couldn’t reach before. This includes abandoned cart recoveries, re-engaged churned buyers, and paid campaigns that retarget verified profiles instead of anonymous clicks.
Connect this back to KPIs like LTV/CAC ratio, deliverability, and paid ROAS.



.png)

